
Our research explained
Introduction
Learning differences are widely understood as being neurobiological in origin: as such, they remain a long-life condition.
Motor Dysgraphia and Dyslexia are both learning differences where complete diagnosis has to be made by a practitioner qualified to administer the range of standardised assessments required for an accurate diagnosis.
Nevertheless, these learning differences are also characterised by specific difficulties.
The American Psychiatric Association manual, also known as DSM-5, is an authoritative volume describing characteristics where:
- Motor Dysgraphia appears under the umbrella terms of Developmental Coordination Disorder (previously known as Dyspraxia) and affects fine motor skills, including handwriting skills.
- Dyslexia is characterised by problems with accurate or fluent word recognition, poor decoding, and poor spelling abilities. (DSM-5 page 105)
These characteristics can be accurately measured by a computer. Such accurate measurements have led the artificial intelligence community to consider that, given enough data, accurate screenings can be performed by:
- capturing appropriate data from an individual, then
- applying specific algorithms derived from mathematics and computer science which are not prone to the variability of human judgement.
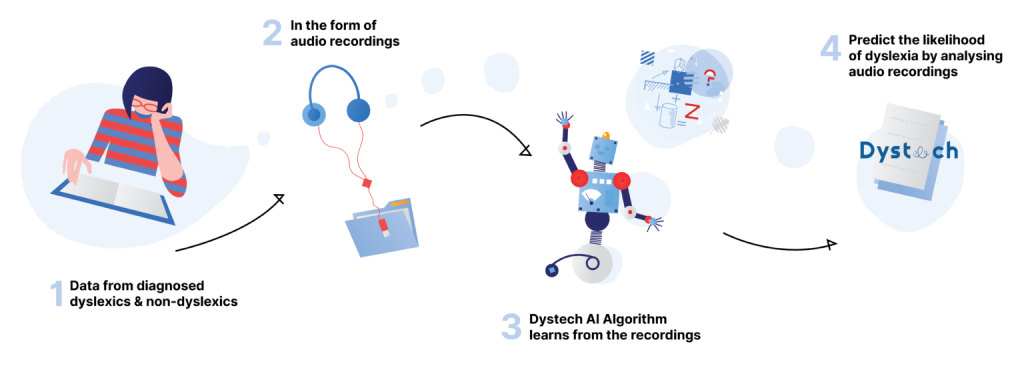
A simple illustration of our research
Scientific publications
- Detecting Dyslexia from Audio Records: An AI Approach (February 2021)
- What 10 years of work on AI & Dyslexia look like? (February 2021, white paper, overview)
- British Dyslexia Association International Conference – Prof. Gilles Richard presentation
- Dyslexia and Dysgraphia prediction: A new machine learning approach (April 2020)
Dystech technology explained
Dyscreen dyslexia screener
During the Dyscreen dyslexia screening process, we record the person being assessed as they read a list of 32 words. 16 words are real English words and 16 are pseudowords or nonsense words, which are generated by artificial intelligence techniques based on the age of the individual being screened. The audio recordings are processed on our server via specific software and we extract 6 metrics, which are important for the likelihood estimate.
Metrics:
- 3 metrics are related to what is known as Reading Reaction Time (RRT). For a given word, the RRT is the interval between the initial display of the word on the screen and when the individual starts to read. We get an average RRT on all words, on real words and on nonsense words.
- 3 other metrics are related to Reading Time (RT) which is an indication of the time it takes to read a word. We get an average RT on all words, both real words and nonsense words.
As can be seen in the figure below (which is based on our data), these reading times highlight a clear discrepancy between standard readers and dyslexic readers.
*The unit of time we measure is millisecond (ms).

We have trained our machine learning algorithm on data gathered from standard readers and dyslexic readers obtained from our educational and clinical partners. Our machine learning predictor currently provides a likelihood of dyslexia with above 90% accuracy by analysing audio recordings from the screenee.
Motor Dysgraphia technology
(coming soon)
During the screening, we ask for an image of handwritten text approximately 4 to 5 lines in length. It is recommended our instructions are followed when taking the picture as this will simplify our processing and make our measurement more accurate. We do not check the spelling of the text as the relevance of it for screening motor dysgraphia is debatable. From the text, we extract 8 features:
- Slant: The slant corresponds to the direction of the handwriting. We normalise this by converting the values from 0 (left slant) to 1 (right slant).
- Pressure: The estimated pressure of the handwriting from 0 (low) to 1 (high).
- Amplitude: This is the average gap size between x-height and ascending/descending letters, from 0 (low) to 1 (high).
- Letter Spacing: This estimates the average spacing between letters in a word, from 0 (small spacing) to 1 (large spacing). Typically, a cursive writing style will lead to 0.
- Word spacing: This estimates the average spacing between words in a sentence, from 0 (small spacing) to 1 (large spacing).
- Slant Regularity: from 0 (not regular) to 1 (highly regular).
- Size Regularity: from 0 (not regular) to 1 (highly regular). This measures whether the same letters vary in size within the text.
- Horizontal Regularity: from 0 (the text doesn’t follow a horizontal line) to 1 (the text follows a horizontal line).
Here is an example for slant feature:

We have manually extracted these measurements from every picture we have received (approximately 1500), including examples from standard writers and dysgraphic writers.
Once the writing sample has been submitted, classical processing and machine learning methods are applied to finally provide an algorithm able to:
- automatically extract the measurements from the new picture, and
- provide a likelihood of motor dysgraphia for the individual who has submitted the writing sample.